
왜 LLM이 내 문서를 사용하지 않나요?
팁: 이 페이지는 LLM이 질문할 때 왜 문서를 사용하지 않는지에 대한 심층 분석입니다.
다행히도, 실제로는 해결하기 간단합니다! 이 아이디어는 TeamplGPT뿐만 아니라 다른 경우에도 적용됩니다.
우리는 매주 여러 번 이 질문을 받습니다. LLM이 내 문서에 대해 "모든 것을 알고 있는 것처럼 보이지 않는다"고 혼란스러워하거나 심지어 화를 내는 사람들이 있습니다.
이 현상을 이해하려면 먼저 TeamplGPT 내부에서 RAG(정보 검색 강화 생성)가 어떻게 작동하는지에 대한 혼란을 풀어야 합니다.
이 내용은 깊이 있는 기술적 설명은 아니지만, 이 글을 읽으면 전통적인 RAG가 어떻게 작동하는지 전문가가 될 것입니다.
LLM은 전지전능하지 않습니다
불행히도, LLM은 아직 자각이 없으며, 가장 강력한 모델을 사용하더라도 모델이 "당신이 의미하는 바를 알 수 있다"고 기대하는 것은 비현실적입니다.
말할 필요도 없이, 많은 요인과 이동 요소가 LLM의 출력과 중요성에 영향을 미칠 수 있으며, 각 요인이 특정 사용 사례에 따라 출력에 영향을 줄 수 있습니다!
LLM은 자가 반성하지 않습니다
TeamplGPT에서는 전체 파일 시스템을 읽고 이를 LLM에 보고하지 않습니다. 이는 99%의 경우에 토큰을 낭비하기 때문입니다.
대신, 사용자의 쿼리는 문서 텍스트의 벡터 데이터베이스에 대해 처리되며, "관련성 있는" 문서에서 4-6개의 텍스트 청크를 반환받습니다.
예를 들어, 수백 개의 레시피가 있는 작업 공간이 있다고 가정해 봅시다. "고칼로리 식사 3개의 제목을 가져와"라고 묻지 마세요. 이 LLM은 이를 거부할 것입니다! 왜 그럴까요?
문서 채팅봇용 RAG를 사용할 때 전체 문서 텍스트는 대부분의 LLM 컨텍스트 윈도우에 맞을 수 없습니다. 문서를 텍스트 청크로 나누고 이러한 청크를 벡터 데이터베이스에 저장하면 쿼리를 기반으로 관련 정보를 "보강"하여 LLM의 기본 지식에 추가하기 쉬워집니다.
전체 문서 세트는 모델에 "임베드"되지 않습니다. 모델은 각 문서에 무엇이 있는지, 문서가 어디에 있는지 모릅니다.
이것이 여러분이 원하는 것이라면, 여러분은 에이전트를 생각하고 있는 것입니다. 이는 곧 TeamplGPT에 추가될 예정입니다.
그렇다면 TeamplGPT는 어떻게 작동하나요?
TeamplGPT를 프레임워크 또는 파이프라인으로 생각해 봅시다.
-
작업 공간이 생성됩니다. LLM은 이 작업 공간에 임베드된 문서만 "볼 수" 있습니다. 문서가 임베드되지 않은 경우, LLM은 해당 문서의 내용을 볼 수 없거나 접근할 수 없습니다.
-
문서를 업로드하면 "작업 공간으로 이동"하거나 문서를 "임베드"할 수 있습니다. 업로드는 문서를 텍스트로 변환하는 것뿐입니다.
-
"문서를 작업 공간으로 이동"합니다. 이는 2단계의 텍스트를 더 쉽게 소화할 수 있는 청크로 나눕니다. 그런 다음 이러한 청크는 임베더 모델로 전송되어 벡터라고 하는 숫자 목록으로 변환됩니다.
-
이 숫자 문자열은 벡터 데이터베이스에 저장되며 RAG가 기본적으로 작동하는 방식입니다. 이 단계에서 관련 텍스트가 함께 유지된다는 보장은 없습니다! 이는 현재 활발히 연구 중인 분야입니다.
-
채팅 상자에 질문을 입력하고 전송 버튼을 누릅니다.
-
사용자의 질문도 문서 텍스트와 마찬가지로 임베드됩니다.
-
벡터 데이터베이스는 "가장 가까운" 청크 벡터를 계산합니다. TeamplGPT는 "낮은 점수" 텍스트 청크를 필터링합니다(이를 수정할 수 있습니다). 각 벡터에는 원래 파생된 텍스트가 첨부되어 있습니다.
중요!
이것은 순전히 의미론적인 과정이 아니므로 벡터 데이터베이스는 "당신이 의미하는 바를 알지 못합니다".
이는 "코사인 거리" 공식을 사용하는 수학적 과정입니다.
그러나 여기서 사용된 임베더 모델 및 기타 TeamplGPT 설정이 가장 큰 차이를 만들 수 있습니다. 다음 섹션에서 자세히 알아보세요.
-
유효한 것으로 간주된 청크는 원래 텍스트로 LLM에 전달됩니다. 그런 다음 이러한 텍스트는 해당 작업 공간의 "시스템 메시지"로 LLM에 추가됩니다. 이 컨텍스트는 시스템 프롬프트 아래에 삽입됩니다.
-
LLM은 시스템 프롬프트 + 컨텍스트, 사용자의 쿼리 및 기록을 사용하여 질문에 최대한 정확하게 답변합니다.
완료.
검색 성능을 어떻게 향상시킬 수 있나요?
TeamplGPT는 사용자가 선택한 LLM, 임베더 및 벡터 데이터베이스에 더 잘 맞도록 작업 공간을 조정할 수 있는 많은 옵션을 제공합니다.
작업 공간 옵션은 가장 쉽게 조정할 수 있는 부분이며 여기에서 시작하는 것이 좋습니다. TeamplGPT는 각 작업 공간에서 몇 가지 기본 가정을 합니다. 이는 일부 사용 사례에는 적합하지만 모두에게 적합하지는 않습니다.
작업 공간 위에 마우스를 올리고 "톱니바퀴" 아이콘을 클릭하면 이러한 설정을 찾을 수 있습니다.
채팅 설정 > 프롬프트
이는 작업 공간의 시스템 프롬프트입니다. 작업 공간이 따를 "규칙 세트"와 쿼리에 응답하는 방식을 정의합니다. 여기에서 특정 프로그래밍 언어, 특정 언어 또는 기타 사항을 정의할 수 있습니다. 이곳에 정의하세요.
채팅 설정 > LLM 온도
이는 LLM이 응답에서 얼마나 "창의적"인지 결정합니다. 이는 모델마다 다릅니다. 숫자가 높을수록 응답이 더 "무작위"해집니다. 낮을수록 더 짧고 간결하며 "사실적"입니다.
벡터 데이터베이스 설정 > 최대 컨텍스트 스니펫
이는 RAG의 "검색" 부분에서 매우 중요한 항목입니다. "LLM에 보낼 관련 텍스트 스니펫 수"를 결정합니다. 직관적으로 "모든 스니펫을 원한다"고 생각할 수 있지만, 각 모델이 처리할 수 있는 토큰 수에는 상한선이 있으므로 불가능합니다. 이 창을 컨텍스트 창이라고 하며, 시스템 프롬프트, 컨텍스트, 쿼리 및 기록과 공유됩니다.
TeamplGPT는 모델이 오버플로우되면 데이터를 컨텍스트에서 잘라내므로 이를 피하려면 값을 4-6 사이로 유지하는 것이 좋습니다. Claude-3와 같은 큰 컨텍스트 모델을 사용하는 경우 더 높게 설정할 수 있지만, 컨텍스트에 너무 많은 "노이즈"가 있으면 LLM이 응답을 생성하는 데 혼란을 줄 수 있습니다.
벡터 데이터베이스 설정 > 문서 유사성 임계값
이 설정은 여러분이 겪고 있는 문제의 원인일 수 있습니다! 이 속성은 쿼리와 관련이 없을 가능성이 높은 낮은 점수의 벡터 청크를 필터링합니다. 이는 수학적 값에 기반한 것으로 실제 의미론적 유사성을 기반으로 하지 않기 때문에 답변을 포함한 텍스트 청크가 필터링될 수 있습니다.
환각이나 잘못된 LLM 응답을 받고 있다면 이를 제한 없음으로 설정해야 합니다. 기본 최소 점수는 20%로 설정되어 있는데, 이는 일부 사용 사례에 적합하지만 계산된 값은 여러 요인에 따라 다릅니다:
- 사용된 임베딩 모델(차원 및 특정 텍스트 벡터화 능력)
- 예: 영어 텍스트를 벡터화하는 데 사용된 임베더는 만다린 텍스트에는 적합하지 않을 수 있습니다.
- 기본 임베더는 https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 (opens in a new tab) 입니다.
- 특정 작업 공간 내 벡터 밀도.
- 벡터가 많을수록 실제로 관련이 없는 노이즈와 일치할 가능성이 높습니다.
- 쿼리: 이는 일치하는 벡터의 기준입니다. 모호한 쿼리는 모호한 결과를 가져옵니다.
문서 고정
위의 설정이 아무런 변화를 가져오지 않는다면, 문서 고정이 좋은 해결책이 될 수 있습니다.
문서 고정은 문서의 전체 텍스트를 컨텍스트 창에 삽입하는 것입니다. 컨텍스트 창이 이 정도의 텍스트를 허용하면 전체 텍스트 이해와 훨씬 나은 답변을 얻을 수 있지만 속도와 비용이 증가할 수 있습니다.
문서 고정은 컨텍스트 창에 완전히 맞을 수 있거나 해당 작업 공간의 사용 사례에 매우 중요한 문서에만 예약되어야 합니다.
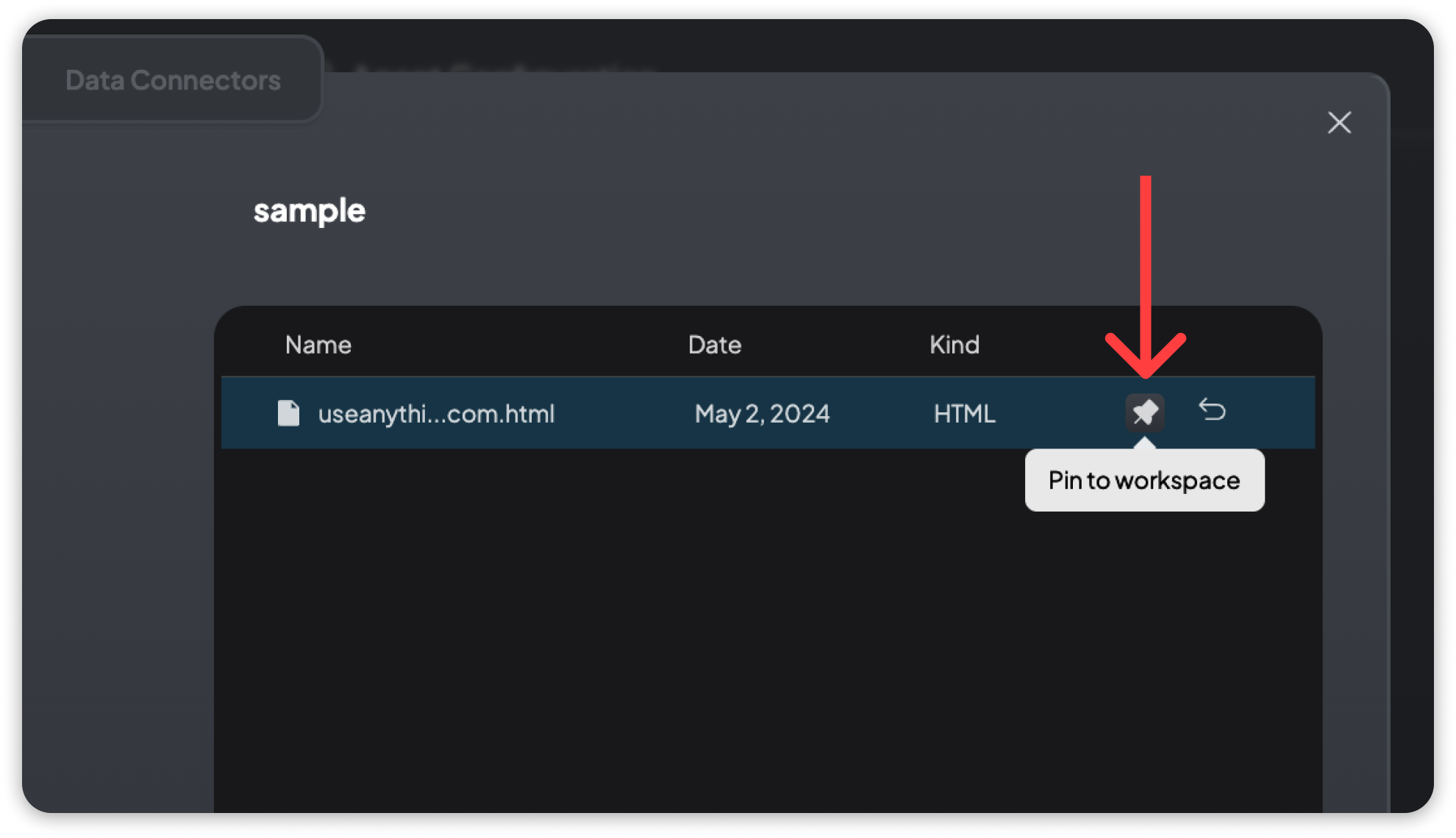
이미 임베드된 문서만 고정할 수 있습니다. 푸시핀 아이콘을 클릭하면 해당 문서에 대해 이 설정이 전환됩니다.